MLPC(Multilayer Perceptron Classifier),多层感知器分类器,是一种基于前馈人工神经网络(ANN)的分类器。Spark中目前仅支持此种与神经网络有关的算法,在ord.apache.spark.ml中(并非mllib)。本文通过代码来演示用Spark运行MLPC的一个小例子。
1 算法简介
多层感知器是一种多层的前馈神经网络模型。
所谓前馈型神经网络,指其从输入层开始只接收前一层的输入,并把计算结果输出到后一层,并不会给前一层有所反馈,整个过程可以使用有向无环图来表示。该类型的神经网络由三层组成,分别是输入层(Input Layer),一个或多个隐层(Hidden Layer),输出层(Output Layer),如图所示: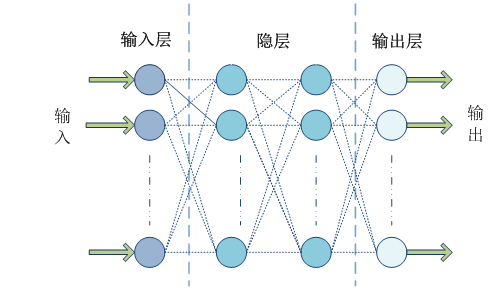
MLPC采用了BP(反向传播,Back Propagation) 算法,BP算法的学习目的是对网络的连接权值进行调整,使得调整后的网络对任一输入都能得到所期望的输出。BP 算法名称里的反向传播指的是该算法在训练网络的过程中逐层反向传递误差,逐一修改神经元间的连接权值,以使网络对输入信息经过计算后所得到的输出能达到期望的误差。
Spark的多层感知器隐层神经元使用sigmoid函数作为激活函数,输出层使用的是softmax函数。
MLPC可调的几个重要参数:
- featuresCol:输入数据 DataFrame 中指标特征列的名称。
- labelCol:输入数据 DataFrame 中标签列的名称。
- layers:这个参数是一个整型数组类型,第一个元素需要和特征向量的维度相等,最后一个元素需要训练数据的标签数相等,如 2 分类问题就写 2。中间的元素有多少个就代表神经网络有多少个隐层,元素的取值代表了该层的神经元的个数。例如val layers = (5,6,5,2)。
- maxIter:优化算法求解的最大迭代次数。默认值是 100。
- predictionCol:预测结果的列名称。
2 运行步骤
2.1 数据说明
MLPC对数据源有严格要求,只能是以下两种:
- DataFrame
使用DataFrame作为数据源时必须指定DataFrame中的标签列和特征列; - LIBSVM格式文本文件
数据格式为:标签 特征ID:特征值 特征ID:特征值……
本例中采用了LIBSVM格式文本文件,数据如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14[xuqm@cu01 ML_Data]$ cat input/sample_multiclass_classification_data.txt
1 1:-0.222222 2:0.5 3:-0.762712 4:-0.833333
1 1:-0.555556 2:0.25 3:-0.864407 4:-0.916667
1 1:-0.722222 2:-0.166667 3:-0.864407 4:-0.833333
1 1:-0.722222 2:0.166667 3:-0.694915 4:-0.916667
0 1:0.166667 2:-0.416667 3:0.457627 4:0.5
……
……
……
2 1:-0.388889 2:-0.166667 3:0.186441 4:0.166667
0 1:-0.222222 2:-0.583333 3:0.355932 4:0.583333
1 1:-0.611111 2:-0.166667 3:-0.79661 4:-0.916667
1 1:-0.944444 2:-0.25 3:-0.864407 4:-0.916667
1 1:-0.388889 2:0.166667 3:-0.830508 4:-0.75
2.2 代码及说明
1 | import org.apache.spark.ml.classification.MultilayerPerceptronClassifier |
3 结果展示
1 | // 计算精度并输出 |

