KMeans是一种典型的聚类算法,本文通过代码来演示用spark运行KMeans算法的一个小例子。
1 算法简介
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把无标签样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值或迭代次数达到阈值。
2 运行步骤
2.1 数据说明
数据格式为:特征1 特征2 特征31
2
3
4
5
60.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
2.2 代码及说明
1 | import org.apache.log4j.{ Level, Logger } |
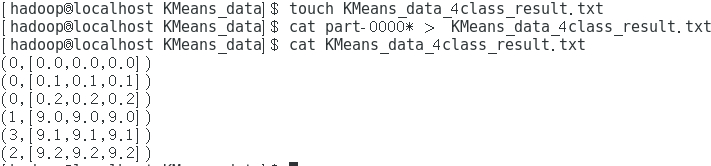
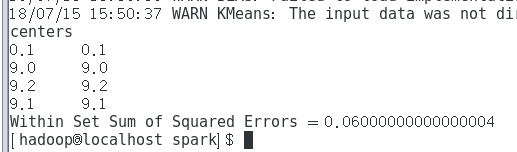
3 结果展示
将结果合成到一个文件中,方便查看: